efficacy endpoints分析的multiplicity
multiplicity
对于efficacy endpoints的分析,诺大一个RCT项目,一般不会只有单独的一个primary endpoint,在primary之外,都会有secondary、exploratory之类多个终点。在同一个研究中对多个检验假设分别进行统计推断,当结果的比较分析次数增多时,这就会引来多重性问题(multiplicity/multiple comparisons),即,使得$I$类错误增大,以至于出现假阳性结论的药物上市的概率增大。
efficacy endpoints
我们这里主要介绍RCT中出现了多个efficacy endpoints时的多重性问题的其中一种解决策略。
提醒大家注意,当RCT的结论完全服从于primary endpoint的结论时,无论ensondary、exploratoty endpoints多少个,此时,不需要考虑multiplicity。
针对同一问题不同方面的不同endpoints,虽然有primary、secondary之分,如果我们认为次要指标的结果将有利于试验,此时,我们可以采用hierarchical testing的方式来依次进行统计推断。当且仅当上一级假设有统计学意义时,下一级才可以进行统计推断,否则整个序贯检验将被终止。在这种策略下,我们不需要校正$I$类错误。
我们来看一个实际应用这个策略的案例:
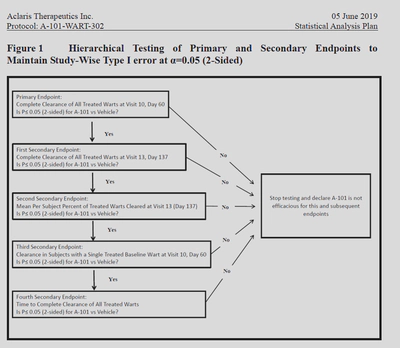
这个项目的SAP我已经放在了知识星球上(https://t.zsxq.com/10qxcDEKD)。
这种gate-keeping的方式,主要用于主要、次要指标共存时的假设检验,也非常好理解:一旦主要指标无统计学意义,则后续一切都将失去意义,无论其是否有统计学意义。类似的做法还有下面这个:
PFS will be analyzed first when approximately 264 events are reached. In line with the gate keeping strategy, ORR will only be assessed for superiority should PFS have demonstrated superiority.
{kind=link}